术语表
图
图是由一组顶点(vertex)和一组能够将两个顶点相连的边(edge)组成的。
顶点的表示
一般使用 0 至 V-1 的数组来表示一张含有 V 个顶点的图中的各个顶点。顶点若是其他符号,仅需将顶点名字与 0 到 V-1 的整数值建立一一对应的关系即可。
边的表示
用 v-w 来表示连接 v 和 w 的边
特殊的图
- 自环,即一条连接一个顶点和其自身的边
- 连接同一对顶点的两条边称为平行边
顶点的度数
为依附于它的边的总数
路径
路径是由边顺序连接的一系列顶点。简单路径是一条没有重复顶点的路径。路径的长度为其中所包含的边数。我们用类似 u-v-w-x 的记法来表示 u 到 x 的一条路径。
环
环是一条至少含有一条边且起点和终点相同的路径。简单环是一条(除起点和终点必相同)不含有重复顶点和边的环。环的长度为其中所含边数。用 u-v-w-x-u 表示从 u 到 v 到 w 到 x 再回到 u 的一条环。
连通
当两个顶点之间存在一条连接双方的路径时,我们称一个顶点和另一个顶点是连通的。
连通图
从任意一个顶点都存在一条路径到达另一个任意顶点,叫连通图。
非连通图
无环图
不包含环的图。
图的密度
图的密度是指已经连接的顶点对占所有可能被连接的顶点对的比例。在疏密图中,被连接的顶点对很少;在稠密图中,只有少部分顶点对之间没有边连接。
无向图的数据类型
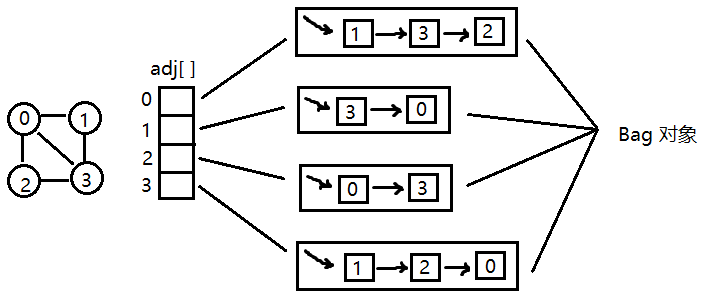
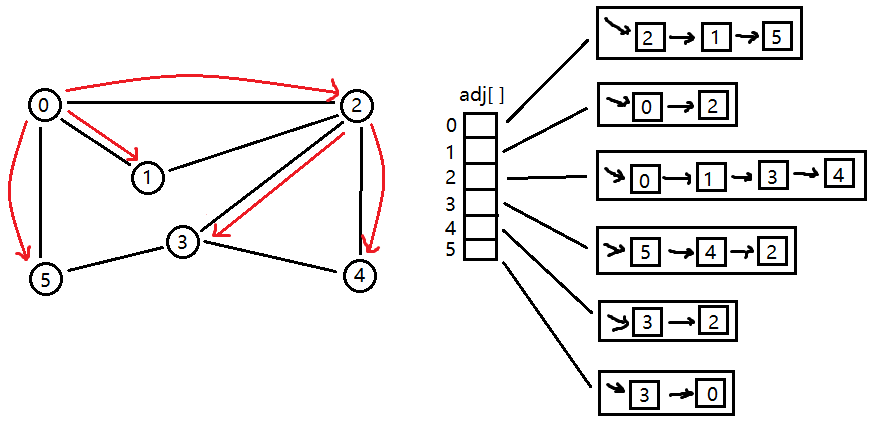
上图所示,左边就是原图,右边是邻接表的数据结构来表示原图。邻接表 adj 将每个顶点的所有邻接点都保存在该顶点对应的元素所指向的一张链表中,且链表中存储顶点的顺序是无所谓的,这里链表用 Bag 对象表示。
如下是 Graph 类,值得注意的是无向图中每条边都会出现两次,即当存在一条连接 v 与 w 的边时,w 会出现在 v 的链表中,v 也会出现在 w 的链表中,这样就可以理解 addEdge 了。
public class Graph {
private static final String NEWLINE = System.getProperty("line.separator"); // 换行展示
private final int V; // 顶点数目
private int E; // 边的数目
private Bag<Integer>[] adj; // 邻接表
public Graph(int V) {
this.V = V;
this.E = 0;
adj = (Bag<Integer>[]) new Bag[V]; // 创建邻接表
for (int v = 0; v < V; v++) { // 将所有邻接表初始化为空
adj[v] = new Bag<Integer>();
}
}
public Graph(In in) {
this(in.readInt()); // 读取V并将图初始化
int E = in.readInt(); // 读取E
for (int i = 0; i < E; i++) {
int v = in.readInt(); // 读取一个顶点
int w = in.readInt(); // 读取另一个顶点
addEdge(v, w); // 添加一条连接它们的边
}
}
public int V() { return V; }
public int E() { return E; }
public void addEdge(int v, int w) {
adj[v].add(w); // 将w添加到v的链表中
adj[w].add(v); // 将v添加到w的链表中
E++;
}
public Iterable<Integer> adj(int v){ // 获取顶点 v 的所有邻接点
return adj[v];
}
public String toString() { // 以字符串显示邻接表
StringBuilder s = new StringBuilder();
s.append(V + " vertices, " + E + " edges " + NEWLINE);
for (int v = 0; v < V; v++) {
s.append(v + ": ");
for (int w : adj[v]) {
s.append(w + " ");
}
s.append(NEWLINE);
}
return s.toString();
}
public static void main(String[] args) {
Graph G = new Graph(new In());
StdOut.println(G); // 等价于调用 G.toString()
}
}
运行结果:
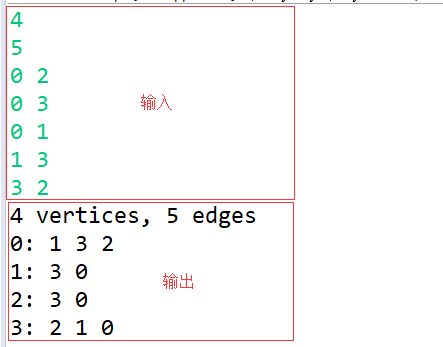
注意:输入部分来构建图 1。输入 4、5 分别表示图由 4 个顶点、5 条边组成。之后输入 "0 2"、"0 3" 等表示图中顶点相连的边,且输入 "0 2" 和 "2 0" 是一样的效果,选择其一输入即可。
深度优先搜索
图的深度优先搜索(Depth First Search),简称 DFS,和树的先序遍历比较类似。
它的思想:
用一个递归 dfs 方法来遍历所有顶点,在访问一个顶点时,将它标记为已访问,再递归地访问它的所有没有被标记过的邻接点。直到所有与起点 s 连通的顶点都被访问。
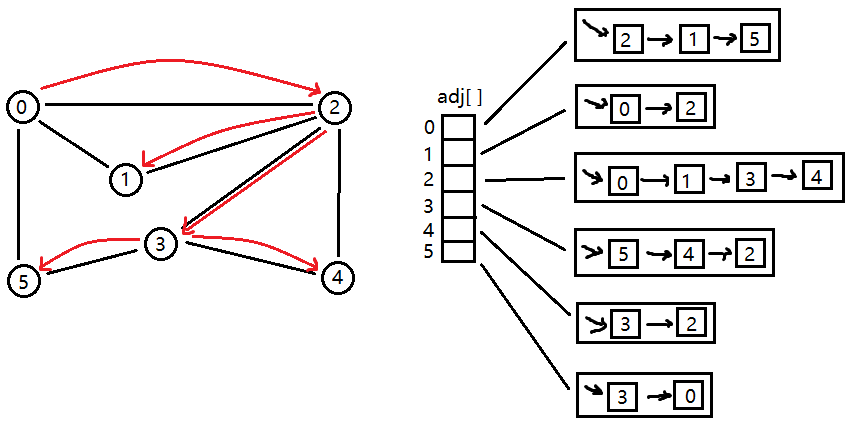
深度优先搜索的步骤:
1、访问起始点 0
2、访问 2。在第1步后,接下来应该访问 0 的邻接点,即 "2、1、5" 中的一个。 0 的邻接点在邻接表中对应的顺序是 "2->1->5",即先访问 2。
3、访问 1。在第2步后,接下来访问 2 的邻接点。由于 0 以标记 marked 为访问状态,所以访问下一个即 1。
4、访问 3。在第3步后,本来应该以 1 为始,访问其邻接点 "0、2"。但是 "0、2" 都已访问过了,所以只能回退到 2 这个点,2 的邻接点 "0、1" 都 marked 为已访问状态,顾 2 继续向 3 移动。
5、访问 5。在第4步后,访问 3 的邻接点,即访问 5。
6、访问 4。5 不能直接访问 0,所以回退到 3,继续由 3 访问剩余的顶点 4。
如上过程,便可遍历所有顶点,因此访问顺序为:0 > 2 > 1 > 3 > 5 > 4
public class DepthFirstSearch {
private boolean[] marked; // 标记访问状态
private int count; // 顶点总数
public DepthFirstSearch(Graph G, int s) { // 指定起点 s
marked = new boolean[G.V()];
dfs(G, s);
}
private void dfs(Graph G, int v) { // 深度优先算法的核心:递归调用
marked[v] = true;
count++;
for(int w : G.adj(v))
if(!marked[w]) dfs(G, w);
}
public boolean marked(int w) { // w 与起点 s 连通吗
return marked[w];
}
public int count() {
return count;
}
}
深度优先搜索的好处在于:一次 dfs 调用,可以将与起点连通的其他所有顶点查询出来,即查找出一个连通子图。
深度优先搜索寻找路径
寻找路径是指从起点 s 到与 s 连通的每个顶点之间的路径。依然以图 2 为例,寻找的是起点 0 到各个连通顶点的路径,例如 0 ~ 1 的路径是 0->2->1,0 ~ 5 的路径是 0->2->3->5 等。
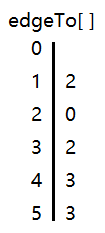
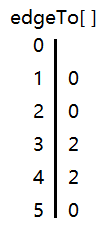
那么何如才能寻找到起点到其他所有顶点的路径呢。有一个很简单的办法,就是用一个数组 edgeTo 表示所有顶点,各个顶点分别记录路径中的前一个顶点。因此,每一个顶点都存着路径中的前一个顶点,那么任何一个顶点都可以顺着前一个顶点找到起点的路径。
举个例子,数组 edgeTo 开了6个空间,下标 0~5,分别对应各个顶点。路径中 5 的前一个点是 3,因此下标 5 位置存着 3;路径中 1 的前一个点是 2,因此下标 1 存着 2。其他顶点可以此类推。
如下代码和 DFS 代码几乎一致,仅增加了 edgeTo 来记录当前顶点路径上的前一个顶点,增加了 pathTo 来返回起点到指定顶点路径。
public class DepthFirstPaths {
private boolean[] marked;
private int[] edgeTo; // 从起点到一个顶点的已知路径上的前一个顶点
private final int s; // 起点
public DepthFirstPaths(Graph G, int s) {
marked = new boolean[G.V()];
edgeTo = new int[G.V()];
this.s = s;
dfs(G, s);
}
private void dfs(Graph G, int v) {
marked[v] = true;
for(int w : G.adj(v))
if(!marked[w]) {
edgeTo[w] = v; // v 是 w 的前一个顶点
dfs(G, w);
}
}
public boolean hasPathTo(int v) {
return marked[v];
}
public Iterable<Integer> pathTo(int v){ // 返回从起点到指定顶点 v 的路径
if(!hasPathTo(v)) return null;
Stack<Integer> path = new Stack<Integer>();
for(int x = v; x != s; x = edgeTo[x]) {
path.push(x);
}
path.push(s);
return path;
}
public static void main(String[] args) {
In in = new In();
Graph G = new Graph(new In());
int s = 0;
DepthFirstPaths dfs = new DepthFirstPaths(G, s);
StdOut.println("输出起点 "+s+" 到各个顶点路径:");
for (int v = 0; v < G.V(); v++) {
if (dfs.hasPathTo(v)) {
StdOut.printf("%d to %d: ", s, v);
for(int x : dfs.pathTo(v)) {
if (x == s) StdOut.print(x);
else StdOut.print("-" + x);
}
StdOut.println();
}
}
}
}
运行结果:

注意:上面输入部是构建图 2
广度优先搜索寻找路径
广度优先搜索算法(Breadth First Search),又称为"宽度优先搜索"或"横向优先搜索",简称BFS。
它的思想:
广度优先搜索的原理类似于树的层序遍历,并且算法也使用了队列。它从起点开始,其所有邻接点入队,选择一个邻接点出队,其对应邻接点再入队,以此类推。
广度优先搜索的步骤:
1、访问 0
2、顶点 "2、1、5" 依次入队。步骤 1 后,0 出队,其所有邻接点 "2、1、5" 入队。
3、访问 2。步骤 2 后,顶点 2 出队,其邻接点 "3、4" 入队,由于 "0、1" 已经入队了,所以不会重复入队。
4、访问 1。步骤 3 后,顶点 1 出队,且无入队操作,即访问 1。
5、访问 5。同上
4、访问 3。同上
5、访问 4。同上
如上过程,便可遍历所有顶点,因此访问顺序为:0 > 2 > 1 > 5 > 3 > 4
BFS 寻路:
广度优先搜索寻路和深度优先搜索寻路思路一样,也是采用 edgeTo 数组记录前一个顶点。但是区别在于广度优先搜索的路径,一定是最短路径,要证明很简单,这里就不给出证明过程了。举个例子, 0~5 在广度中路径是 "0->5",请问还能找出从顶点 0 到 5 比它还短的路线吗。
代码展示
public class BreadthFirstPaths {
private boolean[] marked;
private int[] edgeTo;
private final int s; // 起点
public BreadthFirstPaths(Graph G, int s){
marked = new boolean[G.V()];
edgeTo = new int[G.V()];
this.s = s;
bfs(G, s);
}
private void bfs(Graph G, int s){
Queue<Integer> queue = new Queue<Integer>();
marked[s] = true; // 标记起点
queue.enqueue(s); // 将它加入队列
while(!queue.isEmpty()){
int v = queue.dequeue(); // 从队列中删去下一个顶点
for(int w : G.adj(v)){
if(!marked[w]){
edgeTo[w] = v;
marked[w] = true; // 标记它
queue.enqueue(w); // 并将它添加到队列中
}
}
}
}
public boolean hasPathTo(int v){
return marked[v];
}
public Iterable<Integer> pathTo(int v){
if(!hasPathTo(v)) return null;
Stack<Integer> path = new Stack<Integer>();
for(int x = v; x != s; x = edgeTo[x]) {
path.push(x);
}
path.push(s);
return path;
}
public static void main(String[] args) {
In in = new In();
Graph G = new Graph(new In());
int s = 0;
BreadthFirstPaths bfs = new BreadthFirstPaths(G, s);
StdOut.println("输出起点 "+s+" 到各个顶点路径:");
for (int v = 0; v < G.V(); v++) {
if (bfs.hasPathTo(v)) {
StdOut.printf("%d to %d: ", s, v);
for(int x : bfs.pathTo(v)) {
if (x == s) StdOut.print(x);
else StdOut.print("-" + x);
}
StdOut.println();
}
}
}
}
运行结果:

注意:上面输入部是构建图 3
连通分量
连通图:
在无向图中若任意两个不同的顶点vi和vj都连通,则称为连通图。
连通分量:
无向图的极大连通子图称为连通分量。极大表示连通子图不能再大,再多一个顶点就不连通了。如下图 "0、1、2、3" 就是一个连通分量,"4、5" 是另一个连通分量。
注意:
- 任何连通图的连通分量只有一个,即是其自身
- 非连通的无向图有多个连通分量
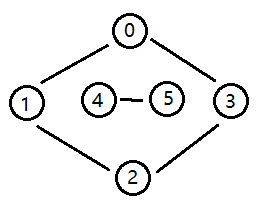
上面深度和广度都是以连通图做为例子,那这种非连通图是如何遍历呢。思路很简单,for 循环查找每一个没有被标记的顶点并调用 dfs 来标记和它相邻的所有顶点。举个例子,第一次调用 0,用 dfs 来标记所有与 0 连通的顶点 "1、2、3";再往后,for 循环到顶点 4 时,再调用 dfs 来标记所有与 4 连通的顶点 "5",即完成了所有连通分量的遍历。
public class CC {
private boolean[] marked;
private int[] id; // 为所有顶点设置不同连通分量标识符
private int count; // 记录图中连通分量总数
public CC(Graph G){
marked = new boolean[G.V()];
id = new int[G.V()];
for(int s = 0; s < G.V(); s++){ // for 循环所有顶点,来遍历所有连通分量
if(!marked[s]){
dfs(G,s);
count++;
}
}
}
private void dfs(Graph G, int v){
marked[v] = true;
id[v] = count;
for(int w : G.adj(v))
if(!marked[w])
dfs(G,w);
}
public boolean connected(int v, int w){
return id[v] == id[w];
}
public int id(int v){
return id[v];
}
public int count(){
return count;
}
public static void main(String[] args) {
Graph G = new Graph(new In());
CC cc = new CC(G);
int M = cc.count();
StdOut.println(M + "components");
Bag<Integer>[] components;
components = (Bag<Integer>[]) new Bag[M];
for(int i = 0; i < M; i++)
components[i] = new Bag<Integer>();
for(int v = 0; v < G.V(); v++)
components[cc.id(v)].add(v);
for(int i = 0; i < M; i++){
for(int v:components[i])
StdOut.print(v + " ");
StdOut.println();
}
}
}
运行结果:
